pick你的第一个人形机器人——青龙强化学习环境
一、使用docker创建环境
1.1 创建容器
拉取合适的cuda版本镜像创建容器,这里拉取cuda12.2.2的镜像
1 | docker run --gpus all --name OpenLoong -e NVIDIA_DRIVER_CAPABILITIES=all -v /etc/localtime:/etc/localtime:ro -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=unix$DISPLAY -e GDK_SCALE -e GDK_DPI_SCALE --net=host --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/kemove/dockerShareFile/OpenLoong:/workspace/data -it nvidia/cuda:12.2.2-devel-ubuntu20.04 bash |
1.2 在容器中安装常用的包
1 | # 获取最新软件包 |
一条命令安装
1 | apt-get update && |
1.3 安装Python3.8和常用包
1 | apt-get install python3.8 |
1.4 安装Pytorch
1 | pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 |
—————————————-本地安装———————————————————-
最近感受到的大趋势是具身智能,强化学习,模仿学习做人型机器人,这个赛道很火,颇有前些年全力投入做自动驾驶的架势,正好最近用强化学习解决POMDP问题接触到了强化学习,闲逛博客发现了上海人工智能实验室青龙开源强化学习环境。正好以此来练练手,了解了解人型机器人。
一、环境配置
- 本地环境
- 系统:ubuntu22.04
- CPU: Intel(R) Core(TM) i9-14900K
- GPU: NVIDIA GeForce RTX 4090
- Docker version 26.0.0, build 2ae903e
- Driver Version: 535.171.04
- CUDA Version: 12.2
conda安装可以参考我配置pytorch环境的博客
1.创建虚拟环境
1 | conda create -n AzureLoong python=3.8 |
2.激活虚拟环境
1 | conda activate AzureLoong |
3.安装pytorch
1 | pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117 |
4.克隆源码
1 | git clone https://atomgit.com/openloong/gymloong |
5.安装Issac gym
1 | cd ./gymloong/isaacgym/python |
6.测试示例
1 | cd ./examples |
此时有可能会报错,报错信息如下:
1 | ImportError: libpython3.8.so.1.0: cannot open shared object file: No such file or directory |
在命令行中输入以下指令
1 | sudo find / -name libpython3.8.so.1.0 |
找到AzureLoong中的libpython3.8.so.1.0,如图所示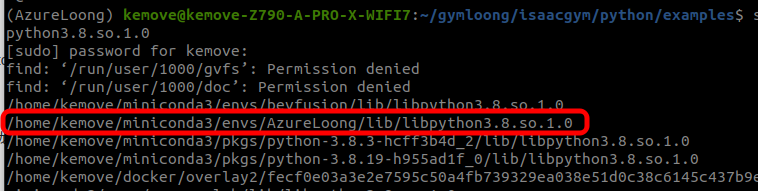
使用以下命令将其复制到/usr/lib目录下
1 | sudo cp /home/kemove/miniconda3/envs/AzureLoong/lib/libpython3.8.so.1.0 /usr/lib/ |
重新以下执行指令,出现以下界面说明安装成功
1 | cd ./examples |
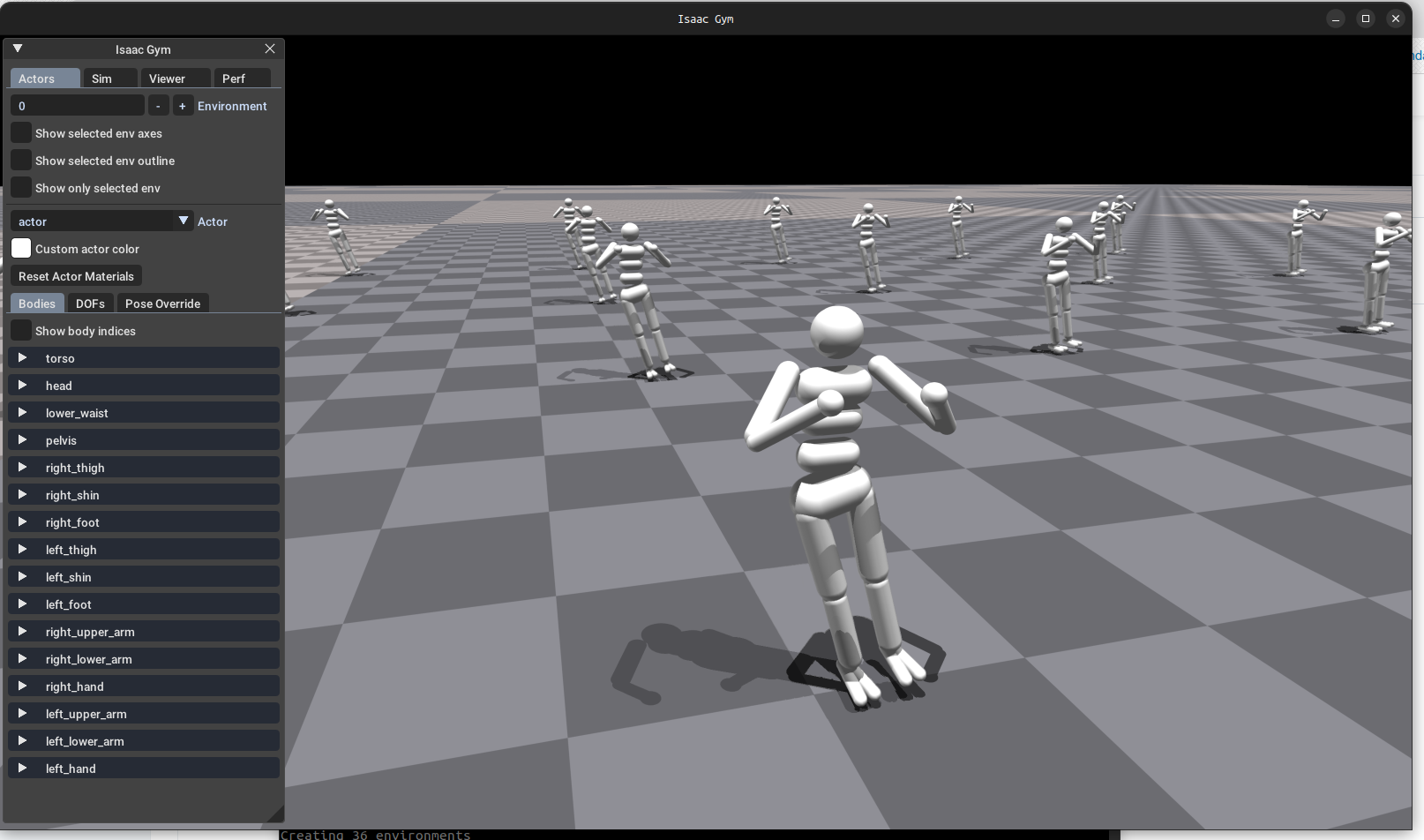
7.安装gpu_rl
1 | ##注意这里使用自己的路径,我这里使用的是本地的绝对路径 |
这里会报一个错,查询发现是setuptools版本太高了,重新安装其指定的版本,然后重新执行安装gpu_rl的指令即可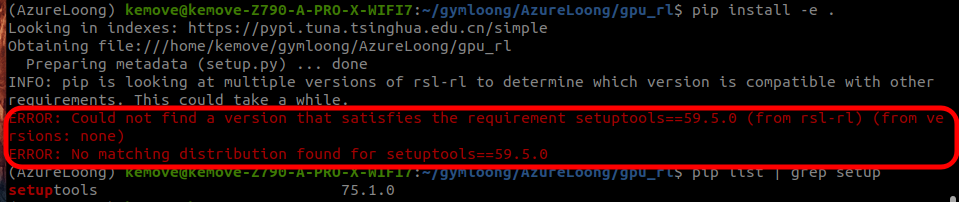
1 | ##安装指定版本 |
8.安装gpuGym
1 | ##注意这里使用自己的路径,我这里使用的是本地的绝对路径 |
9.安装WandB
1 | pip install wandb |
二、开始训练
1.进入到训练脚本所在的路径
1 | ##注意这里使用自己的路径,我这里使用的是本地的绝对路径 |
2.执行以下指令开始训练
1 | python train.py --task=AzureLoong |
训练正常开始会弹出以下画面,按V暂停可视化,命令行中显示了每轮训练中奖励的平均数值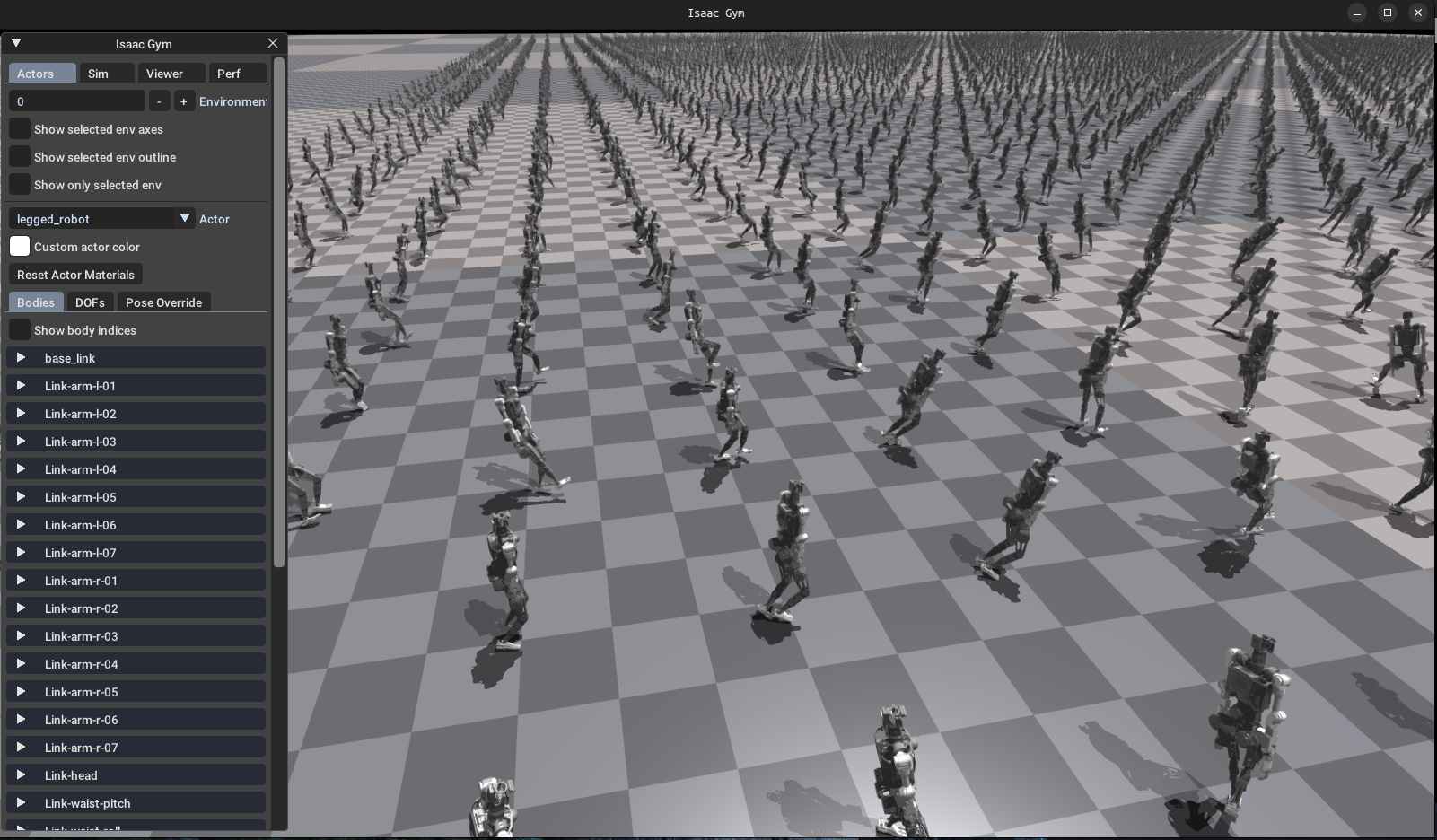
三、训练成果
训练结束后,输入以下指令展示训练的结果
1 | python play.py --task=AzureLoong |
训练结果如下图所示,图中的小点点是一个个小机器人,它们跑到了四面八方,目前我还不理解这结果能说明什么,等以后再研究吧
目前只是跑通了训练的demo,该框架的研究以后再补坑,先研究决策规划去了。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.

